Over the last year and a half, I’ve been working on my first-ever production machine learning project! Here are my assorted notes on the experience.
Background
We’ve built an Optical Music Recognition (OMR) system for Soundslice — see the formal announcement here. Basically it’s a way of converting PDFs and images of sheet music into machine-readable semantic data:

You can think of it as OCR for music notation. Rather than being stuck with a static PDF, you can instead manipulate the underlying music — play it back, edit it in our web-based editor, sync it with a YouTube video, transpose it to other keys, visualize it on a piano keyboard and all the other lovely features that make Soundslice the web’s best music learning experience.
OMR is an inherently hard problem, significantly more difficult than text OCR. For one, music symbols have complex spatial relationships, and mistakes have a tendency to cascade. A single misdetected key signature might result in multiple incorrect note pitches. And there’s a wide diversity of symbols, each with its own behavior and semantics — meaning the problems and subproblems aren’t just hard, there are many of them.
As somebody who’s rather obsessed with creating structure from unstructured data (see: my journalism work), and as a musician, I’ve found the challenge of OMR to be irresistibly interesting.
OMR software has a long history, going back decades. Traditionally it’s used various heuristics — or, put less charitably, hacks. The academic research is full of ideas like: “Let’s look for the largest continuous lines of black pixels. Those must be the staff lines! Oh wait, but if the photo is washed out, we’ve gotta have some tolerance for gray pixels. So let’s binarize the image to get around that. Oh, but binarization means that shadows on the image might get interpreted as blackness, hence losing information, so we need to invent a new type of binarization to mitigate this...” And so forth.
Perhaps not surprisingly, the resounding opinion of musicians (and my own experience) of OMR software is: it sucks. Maybe it works OK on pristine vector PDFs that were generated by modern applications, but dealing with scans of old music or blurry/wavy/badly-lit photos is a disaster.
Now, I don’t want to poo-poo competitors. My hat is respectfully off to anybody working on this technology — which I believe is a much more noble pursuit than, say, building an advertising or user-tracking system. Rather, I’m providing historical context to give a sense of the state of the market, despite developers’ best intentions.
So what’s the Soundslice take on doing better OMR? It started with the realization that machine learning for image processing has gotten really good. The algorithms and pretrained models are amazing and, as importantly, the tools have become accessible to people who aren’t full-time ML researchers.
In theory, we could use off-the-shelf machine learning models, fine-tune them on our specific domain, and (with enough training data!) we’d get vastly better results than the old-school heuristic methods. In practice, that’s exactly what we’ve found. Even though our OMR product is still in beta, its accuracy is better than any other OMR software I’ve tried. (Others agree!)
But I don’t mean this to be an ad for Soundslice; it’s just some background context. What follows is my more general learnings about building a production machine-learning system.
The black box
I’ve been a professional programmer for 20 years now. If I had to distill the craft into a single, fundamental sentence, it would be: Give the computer precise instructions in order to achieve a result.
For me, the biggest mind-melting thing about machine learning has been realizing it’s basically the opposite. Rather than giving the computer precise instructions, you give the computer the result and it deduces the instructions.
Seeing that statement written so plainly, I’m struck that it’s not particularly insightful. I’ve been aware of this concept for my entire programming life. But being aware of it and experiencing it are two different things.
The main practical difference is: when a machine learning system fails, you don’t (and perhaps even can’t!) know why. After years of “normal” programming, I’ve been conditioned to expect that problems are solvable — given enough staring at code, reasoning about it, consuming coffee, etc.
For a machine learning system, if it makes an incorrect decision, there’s very little insight into why. The solution to such problems frequently boils down to: get more training data, and the system will magically improve. (I’m optimistic that the subdiscipline of Explainable AI will eventually solve this.)
This indirectness is incredibly unnatural if you’re used to the idea of software meaning precise instructions. In a way, it’s sort of like parenting. You (obviously!) can’t control your kid’s every actions; the best you can do is provide solid, consistent examples of appropriate behavior...and hope for the best.
Confidence
The flip side is something I’ve come to appreciate about ML systems: confidence values. For each prediction our system makes, it provides a confidence number: “This quarter note has a sharp next to it, and I’m 92.78 percent confident of that.”
Having consistently deterministic confidence values allows for a compelling level of subtlety and control in our product. If a certain ML model has a low confidence, we can opt to ask the user directly. For example, here’s a question the system asked me when it had low confidence on a note’s stem side:
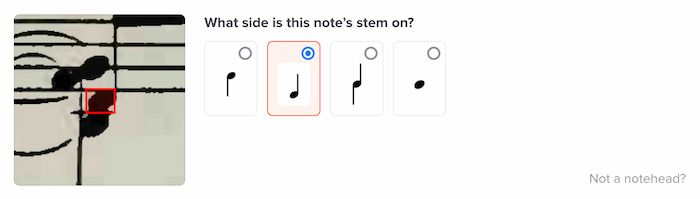
Without ML, in a heuristics-driven system, it would certainly be possible to jerry-rig something that returned confidence levels, but it would essentially require yet another heuristic — another magic number. With ML, you get this for free, and I’ve grown to appreciate that.
Python
The lion’s share of modern machine learning code uses Python. It’s the de facto programming language of machine learning.
As a longtime Python developer, I’m very grateful for this. I get this warm feeling that, many years ago, when I read Mark Pilgrim’s “Dive Into Python,” I happened to have made the right move.
This has given me confidence through some of the more difficult phases of the project. Sometimes I’ll be struggling to figure out some ridiculous ML edge case and I’ll stumble upon Stack Overflow discussions of ML programmers struggling with basic Python syntax or how to pip install something. It’s a good reminder that we all have existing skillsets to bring to the table.
The upshot: If you’re already a Python programmer, you’ll have an inherent advantage when doing modern machine learning. It’s easy to take this for granted.
Training
Training ML models is legitimately fun. You give the system a lot of data, type a few things into the command line, wait (possibly for many hours), and then...you find out if the whole thing actually worked.
This is likely the closest thing modern programmers have to the mainframe computing experience of the mid 20th century, when you’d have to write your program on a punchcard, run it on the machine overnight and come see the results the next day.
You never know what’s going to happen. “Did those extra 2000 training examples actually make this thing better?” If a machine learning project is a mystery novel, then the training (or more precisely, seeing the results of the training) is when the murderer is revealed.
In my experience, the training actually fails a non-zero percentage of the time, due to some weird CUDA thing, or a GPU-out-of-memory error, or the fact that your open-source machine learning library decided to make a backwards-incompatible change (more on this later). But that just adds to the excitement if the whole thing actually works.
The role of creativity
I’ve been pleasantly surprised at the level of creativity involved in this type of work. It’s more than just getting a bunch of data and telling the computer to detect patterns.
Given my unsophisticated knowledge of neural-network internals and techniques, I’m not yet comfortable building a custom network. We’ve relied on off-the-shelf network architectures and open-source tools.
But the surprising thing is: even if you’re using an off-the-shelf ML library, there’s still a lot of creativity involved in how you use it, totally separate from the network architecture itself.
For our project, this has been things like:
- What types of objects are we trying to detect? Do we do super low-level stuff like note stems, bar lines, staff lines and noteheads — or higher level concepts? Or some combination?
- How do the wealth of attributes for a given musical note — its pitch, its accidental, its rhythm, etc. — get posed as machine learning problems?
- What’s the minimal amount of information we need to detect in order to be able to reconstruct the music semantically?
This has been the most interesting aspect of the project for me, and it doesn’t really require deep machine-learning knowledge — just a basic understanding. Domain-specific knowledge is much more important.
If you asked me to identify Soundslice’s “secret sauce” when it comes to our OMR product, I’d say two things: our dataset plus our models’ “point of view” (how they look at an image, how they interact with one another and how the whole thing is orchestrated). Neither of these things requires a particularly deep knowledge of machine learning — which is good news for anybody who wants to work with these technologies but hasn’t gotten a Ph.D. in deep learning.
The researcher/practitioner divide
A few aspects of the machine learning world really underscore how nascent of a field it is. First, stuff changes fast! New algorithms, new datasets, new ideas — it’s hard to keep track of. I recommend the Roboflow blog for the latest developments in ML image recognition, if you can endure the product marketing.
Second, lots of ML open-source code was clearly made by researchers, not practitioners. By this, I mean: it’s poorly documented, it’s hard to deploy, it makes backwards incompatible changes at a moment’s notice, it doesn’t use particularly beautiful Python, it doesn’t even have proper release numbers.
Here I don’t mean to pass judgment, because clearly having access to open-source code is very valuable in itself, and I’m grateful for that.
I’m also fondly reminded of when, in the early days of Django, I refused to do an actual release, saying “If people want to use it, they can just use the SVN checkout.” I’m older (and a bit more boring?) now.
Putting models in production
Relatedly, that brings me to deployment. We’re still in the Wild West days of deploying ML models. Roughly 99.9% of documentation for any given deep-learning code is about the fun stuff, like training, but deploying is nearly always an afterthought (if it even is a thought).
The single thing I most want to see some company build: an easy way to deploy models on GPUs.
But this is all kind of OK, because as a web developer I’m completely comfortable building websites and APIs. A nice upshot here is: skills transfer. You might not have any experience in ML, but there’s a good chance some of your other programming experience is still useful. Which brings me to:
Internal tools
Obviously, one of the most important things for a machine-learning system is the training data. The more, the better. The more diverse, the better.
One of the best things we’ve done in this project was to build a bespoke training-data-management system, specifically for music notation. Sure, many image annotation products are on the market — I tried dozens of them — but at the end of the day, none are as good as the system you craft precisely for your own needs.
This has helped us stay nimble through the inevitable twists and turns of a long-term project. Data-model adjustments, wild experiments, changes to our approach: all were no problem because we built our own system, whereas using a third-party tool would have severely constrained us.
I’m not sure how far this advice generalizes for the common case. But if your team has web development capability, keep in mind this could give you a solid advantage when it comes to managing training data.
Closing thought
All in all, I’ve found this project to be one of the most interesting and intellectually rewarding of my career. Fortunately, it’s just getting started — there’s more training data to get, more models to train, more types of notation to support, more edge cases to handle. We’ll post updates to the Soundslice blog as the system improves.
Want more? Follow me on Mastodon for small stuff that doesn’t merit a full blog post.